Content from Before we Start
Last updated on 2023-07-11 | Edit this page
Overview
Questions
- How to find your way around RStudio?
- How to interact with R?
- How to manage your environment?
- How to install packages?
Objectives
- Install latest version of R.
- Install latest version of RStudio.
- Navigate the RStudio GUI.
- Install additional packages using the packages tab.
- Install additional packages using R code.
What is R? What is RStudio?
The term “R” is used to refer to both the programming
language and the software that interprets the scripts written using
it.
RStudio is currently a very popular way to not only write your R scripts but also to interact with the R software. To function correctly, RStudio needs R and therefore both need to be installed on your computer.
To make it easier to interact with R, we will use RStudio. RStudio is the most popular IDE (Integrated Development Environment) for R. An IDE is a piece of software that provides tools to make programming easier.
Why learn R?
R does not involve lots of pointing and clicking, and that’s a good thing
The learning curve might be steeper than with other software, but with R, the results of your analysis do not rely on remembering a succession of pointing and clicking, but instead on a series of written commands, and that’s a good thing! So, if you want to redo your analysis because you collected more data, you don’t have to remember which button you clicked in which order to obtain your results; you just have to run your script again.
Working with scripts makes the steps you used in your analysis clear, and the code you write can be inspected by someone else who can give you feedback and spot mistakes.
Working with scripts forces you to have a deeper understanding of what you are doing, and facilitates your learning and comprehension of the methods you use.
R code is great for reproducibility
Reproducibility is when someone else (including your future self) can obtain the same results from the same dataset when using the same analysis.
R integrates with other tools to generate manuscripts from your code. If you collect more data, or fix a mistake in your dataset, the figures and the statistical tests in your manuscript are updated automatically.
An increasing number of journals and funding agencies expect analyses to be reproducible, so knowing R will give you an edge with these requirements.
R is interdisciplinary and extensible
With 10,000+ packages that can be installed to extend its capabilities, R provides a framework that allows you to combine statistical approaches from many scientific disciplines to best suit the analytical framework you need to analyze your data. For instance, R has packages for image analysis, GIS, time series, population genetics, and a lot more.
R works on data of all shapes and sizes
The skills you learn with R scale easily with the size of your dataset. Whether your dataset has hundreds or millions of lines, it won’t make much difference to you.
R is designed for data analysis. It comes with special data structures and data types that make handling of missing data and statistical factors convenient.
R can connect to spreadsheets, databases, and many other data formats, on your computer or on the web.
R produces high-quality graphics
The plotting functionalities in R are endless, and allow you to adjust any aspect of your graph to convey most effectively the message from your data.
R has a large and welcoming community
Thousands of people use R daily. Many of them are willing to help you through mailing lists and websites such as Stack Overflow, or on the RStudio community. Questions which are backed up with short, reproducible codesnippets are more likely to attract knowledgeable responses.
Not only is R free, but it is also open-source and cross-platform
Anyone can inspect the source code to see how R works. Because of this transparency, there is less chance for mistakes, and if you (or someone else) find some, you can report and fix bugs.
Because R is open source and is supported by a large community of developers and users, there is a very large selection of third-party add-on packages which are freely available to extend R’s native capabilities.
RStudio extends what R can do, and makes it easier to write R code and interact with R.
A tour of RStudio
Knowing your way around RStudio
Let’s start by learning about RStudio, which is an Integrated Development Environment (IDE) for working with R.
The RStudio IDE open-source product is free under the Affero General Public License (AGPL) v3. The RStudio IDE is also available with a commercial license and priority email support from RStudio, Inc.
We will use the RStudio IDE to write code, navigate the files on our computer, inspect the variables we create, and visualize the plots we generate. RStudio can also be used for other things (e.g., version control, developing packages, writing Shiny apps) that we will not cover during the workshop.
One of the advantages of using RStudio is that all the information you need to write code is available in a single window. Additionally, RStudio provides many shortcuts, autocompletion, and highlighting for the major file types you use while developing in R. RStudio makes typing easier and less error-prone.
Getting set up
It is good practice to keep a set of related data, analyses, and text self-contained in a single folder called the working directory. All of the scripts within this folder can then use relative paths to files. Relative paths indicate where inside the project a file is located (as opposed to absolute paths, which point to where a file is on a specific computer). Working this way makes it a lot easier to move your project around on your computer and share it with others without having to directly modify file paths in the individual scripts.
RStudio provides a helpful set of tools to do this through its “Projects” interface, which not only creates a working directory for you but also remembers its location (allowing you to quickly navigate to it). The interface also (optionally) preserves custom settings and open files to make it easier to resume work after a break.
Create a new project
- Under the
Filemenu, click onNew project, chooseNew directory, thenNew project - Enter a name for this new folder (or “directory”) and choose a
convenient location for it. This will be your working
directory for the rest of the day (e.g.,
~/data-carpentry) - Click on
Create project - Create a new file where we will type our scripts. Go to File >
New File > R script. Click the save icon on your toolbar and save
your script as “
script.R”.
The simplest way to open an RStudio project once it has been created
is to navigate through your files to where the project was saved and
double click on the .Rproj (blue cube) file. This will open
RStudio and start your R session in the same directory
as the .Rproj file. All your data, plots and scripts will
now be relative to the project directory. RStudio projects have the
added benefit of allowing you to open multiple projects at the same time
each open to its own project directory. This allows you to keep multiple
projects open without them interfering with each other.
The RStudio Interface
Let’s take a quick tour of RStudio.

RStudio is divided into four “panes”. The placement of these panes and their content can be customized (see menu, Tools -> Global Options -> Pane Layout).
The Default Layout is:
- Top Left - Source: your scripts and documents
- Bottom Left - Console: what R would look and be like without RStudio
- Top Right - Environment/History: look here to see what you have done
- Bottom Right - Files and more: see the contents of the project/working directory here, like your Script.R file
Organizing your working directory
Using a consistent folder structure across your projects will help keep things organized and make it easy to find/file things in the future. This can be especially helpful when you have multiple projects. In general, you might create directories (folders) for scripts, data, and documents. Here are some examples of suggested directories:
-
data/Use this folder to store your raw data and intermediate datasets. For the sake of transparency and provenance, you should always keep a copy of your raw data accessible and do as much of your data cleanup and preprocessing programmatically (i.e., with scripts, rather than manually) as possible. -
data_output/When you need to modify your raw data, it might be useful to store the modified versions of the datasets in a different folder. -
documents/Used for outlines, drafts, and other text. -
fig_output/This folder can store the graphics that are generated by your scripts. -
scripts/A place to keep your R scripts for different analyses or plotting.
You may want additional directories or subdirectories depending on your project needs, but these should form the backbone of your working directory.

The working directory
The working directory is an important concept to understand. It is the place where R will look for and save files. When you write code for your project, your scripts should refer to files in relation to the root of your working directory and only to files within this structure.
Using RStudio projects makes this easy and ensures that your working
directory is set up properly. If you need to check it, you can use
getwd(). If for some reason your working directory is not
the same as the location of your RStudio project, it is likely that you
opened an R script or RMarkdown file not your
.Rproj file. You should close out of RStudio and open the
.Rproj file by double clicking on the blue cube! If you
ever need to modify your working directory in a script,
setwd('my/path') changes the working directory. This should
be used with caution since it makes analyses hard to share across
devices and with other users.
Downloading the data and getting set up
For this lesson we will use the following folders in our working
directory: data/,
data_output/ and
fig_output/. Let’s write them all in
lowercase to be consistent. We can create them using the RStudio
interface by clicking on the “New Folder” button in the file pane
(bottom right), or directly from R by typing at console:
R
dir.create("data")
dir.create("data_output")
dir.create("fig_output")
Interacting with R
The basis of programming is that we write down instructions for the computer to follow, and then we tell the computer to follow those instructions. We write, or code, instructions in R because it is a common language that both the computer and we can understand. We call the instructions commands and we tell the computer to follow the instructions by executing (also called running) those commands.
There are two main ways of interacting with R: by using the console or by using script files (plain text files that contain your code). The console pane (in RStudio, the bottom left panel) is the place where commands written in the R language can be typed and executed immediately by the computer. It is also where the results will be shown for commands that have been executed. You can type commands directly into the console and press Enter to execute those commands, but they will be forgotten when you close the session.
Because we want our code and workflow to be reproducible, it is better to type the commands we want in the script editor and save the script. This way, there is a complete record of what we did, and anyone (including our future selves!) can easily replicate the results on their computer.
RStudio allows you to execute commands directly from the script editor by using the Ctrl + Enter shortcut (on Mac, Cmd + Return will work). The command on the current line in the script (indicated by the cursor) or all of the commands in selected text will be sent to the console and executed when you press Ctrl + Enter. If there is information in the console you do not need anymore, you can clear it with Ctrl + L. You can find other keyboard shortcuts in this RStudio cheatsheet about the RStudio IDE.
At some point in your analysis, you may want to check the content of a variable or the structure of an object without necessarily keeping a record of it in your script. You can type these commands and execute them directly in the console. RStudio provides the Ctrl + 1 and Ctrl + 2 shortcuts allow you to jump between the script and the console panes.
If R is ready to accept commands, the R console shows a
> prompt. If R receives a command (by typing,
copy-pasting, or sent from the script editor using Ctrl +
Enter), R will try to execute it and, when ready, will show
the results and come back with a new > prompt to wait
for new commands.
If R is still waiting for you to enter more text, the console will
show a + prompt. It means that you haven’t finished
entering a complete command. This is likely because you have not
‘closed’ a parenthesis or quotation, i.e. you don’t have the same number
of left-parentheses as right-parentheses or the same number of opening
and closing quotation marks. When this happens, and you thought you
finished typing your command, click inside the console window and press
Esc; this will cancel the incomplete command and return you
to the > prompt. You can then proofread the command(s)
you entered and correct the error.
Installing additional packages using the packages tab
In addition to the core R installation, there are in excess of 10,000 additional packages which can be used to extend the functionality of R. Many of these have been written by R users and have been made available in central repositories, like the one hosted at CRAN, for anyone to download and install into their own R environment. You should have already installed the packages ‘ggplot2’ and ’dplyr. If you have not, please do so now using these instructions.
You can see if you have a package installed by looking in the
packages tab (on the lower-right by default). You can also
type the command installed.packages() into the console and
examine the output.

Additional packages can be installed from the ‘packages’ tab. On the packages tab, click the ‘Install’ icon and start typing the name of the package you want in the text box. As you type, packages matching your starting characters will be displayed in a drop-down list so that you can select them.

At the bottom of the Install Packages window is a check box to ‘Install’ dependencies. This is ticked by default, which is usually what you want. Packages can (and do) make use of functionality built into other packages, so for the functionality contained in the package you are installing to work properly, there may be other packages which have to be installed with them. The ‘Install dependencies’ option makes sure that this happens.
Scroll through packages tab down to ‘tidyverse’. You can also type a few characters into the searchbox. The ‘tidyverse’ package is really a package of packages, including ‘ggplot2’ and ‘dplyr’, both of which require other packages to run correctly. All of these packages will be installed automatically. Depending on what packages have previously been installed in your R environment, the install of ‘tidyverse’ could be very quick or could take several minutes. As the install proceeds, messages relating to its progress will be written to the console. You will be able to see all of the packages which are actually being installed.
Because the install process accesses the CRAN repository, you will need an Internet connection to install packages.
It is also possible to install packages from other repositories, as well as Github or the local file system, but we won’t be looking at these options in this lesson.
Installing additional packages using R code
If you were watching the console window when you started the install of ‘tidyverse’, you may have noticed that the line
R
install.packages("tidyverse")
was written to the console before the start of the installation messages.
You could also have installed the
tidyverse packages by running this command
directly at the R terminal.
Content from Creating a Webpage
Last updated on 2023-07-11 | Edit this page
Overview
Questions
- How can I create a basic webpage?
Objectives
- Use HTML to create and style a static website.
Introduction
Web pages often contain useful information, but we may want to store that information in a form that is suitable for data analysis or to present selected data in a different way. To be able to obtain this information from a web page, it is helpful to understand how web pages are formatted. One way to gain an understanding is to create a basic web page.
Create a Webpage
Open RStudio and within the file menu, choose
New File>HTML File. You should get an empty window to
enter content. Add the following text
HTML
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width" />
<title>An example website</title>
</head>
<body>
<h1> A website</h1>
<p>Websites can contain useful information. Sometimes
we might want to store and use this information in other
forms. Consider the table of inner solar system planets
and their masses taken from
<a href="https://en.wikipedia.org/wiki/Solar_System">Wikipedia</a>.</p>
<table>
<tr>
<th>Planet</th>
<th>Mass</th>
</tr>
<tr>
<td>Mercury</td>
<td>0.55 <i>M<sub>earth</sub></i></td>
</tr>
<tr>
<td>Venus</td>
<td>0.78 <i>M<sub>earth</sub></i></td>
</tr>
<tr>
<td>Earth</td>
<td>1.0 <i>M<sub>earth</sub></i></td>
</tr>
<tr>
<td>Mars</td>
<td>0.107 <i>M<sub>earth</sub></i></td>
</tr>
</table>
</body>
</html>Save this file as basicwebsite.html and then preview it
using File>preview. Confirm that the preview is accurate
by open the file in a web browser.
Examining the file you just entered, notice that there are
annotations which have information about the structure of the content.
The table is enclosed within tags
<table></table> and other tags are used for
header <h1></h1> as well as for a paragraph
<p></p>. This differs from a what you see
is what you get document that you can produce using a word
processor.
Challenge 1: Add licensing information
When you put information online, you may want to let anyone who
accesses that content know how they can use and reuse the content.
Often, a separate licensing page is on many websites. For a single
webpage website, it is reasonable to add a footer with this information.
At the bottom of the text file, between </table> and
</body> add some licensing information such as
<footer>© My Name 2023. <a href="https://creativecommons.org/licenses/by/4.0/">CC-BY-SA-4.0</a></footer>Discuss what types of licensing information you have seen on other websites. Also discuss implications licensing might have for information you obtain from these websites.
Content from Introduction: What is web scraping?
Last updated on 2023-07-11 | Edit this page
Overview
Questions
- What is web scraping and why is it useful?
- What are typical use cases for web scraping?
Objectives
- Introduce the concept of structured data
- Discuss how data can be extracted from web pages
- Introduce the examples that will be used in this lesson
What is web scraping?
Web scraping is a technique for extracting information from websites. This can be done manually but it is usually faster, more efficient and less error-prone to automate the task.
Web scraping allows you to acquire non-tabular or poorly structured data from websites and convert it into a usable, structured format, such as a .csv file or spreadsheet.
Scraping is about more than just acquiring data: it can also help you archive data and track changes to data online.
It is closely related to the practice of web indexing, which is what search engines like Google do when mass-analysing the Web to build their indices. But contrary to web indexing, which typically parses the entire content of a web page to make it searchable, web scraping targets specific information on the pages visited.
For example, online stores will often scour the publicly available pages of their competitors, scrape item prices, and then use this information to adjust their own prices. Another common practice is “contact scraping” in which personal information like email addresses or phone numbers is collected for marketing purposes.
Web scraping is also increasingly being used by scholars to create data sets for text mining projects; these might be collections of journal articles or digitised texts. The practice of data journalism, in particular, relies on the ability of investigative journalists to harvest data that is not always presented or published in a form that allows analysis.
Before you get started
As useful as scraping is, there might be better options for the task. Choose the right (i.e. the easiest) tool for the job.
- Check whether or you can easily copy and paste data from a site into spreadsheet software. This might be quicker than scraping.
- Check if the site or service already provides an API to extract structured data. If it does, that will be a much more efficient and effective pathway. Good examples are the GitHub API, the Mastodon APIs or the YouTube comments API.
- For much larger needs, Freedom of information requests can be useful. Be specific about the formats required for the data you want.
Example: scraping government websites for contact addresses
In this lesson, we will extract contact information from government websites that list the members of various jurisdictions.
Let’s start by looking at the current list of members of the South African parliament, which is available on the South African parliament website.
This is how this page appears in June 2023:
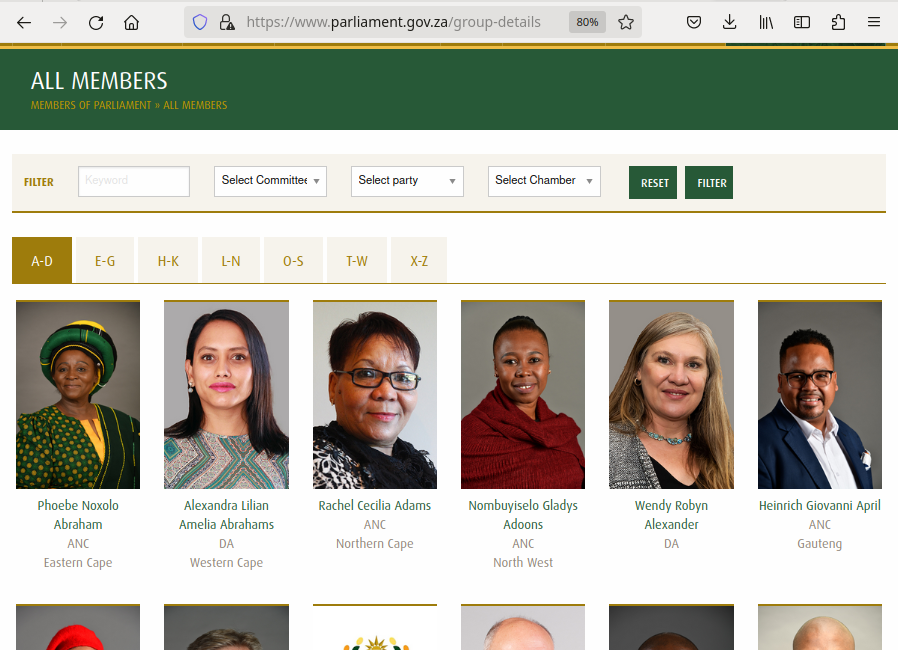 {alt=
{alt=Image showing top part of the South African parliament webite https://www.parliament.gov.za/group-details}
There are several features (circled in the image above) that make the data on this page easier to work with. The search, reorder, refine features and display modes hint that the data is actually stored in a (structured) database before being displayed on this page. The data can be readily downloaded either as a comma separated values (.csv) file or as XML for re-use in their own database, spreadsheet or computer program.
Even though the information displayed in the view above is not labelled, anyone visiting this site with some knowledge of South Africa geography and politics can see what information pertains to the politicians’ names, the geographical area they come from and the political party they represent. This is because human beings are good at using context and prior knowledge to quickly categorise information.
Computers, on the other hand, cannot do this unless we provide them with more information. Fortunately, if we examine the source HTML code of this page, we can see that the information displayed has some structure:
OUTPUT
<div class="cell" id="all-members-tabs-wrapper">
<group-details members='{"a-d":[{"id":1,"full_name":"Phoebe Noxolo Abraham","profile_pic_url":"\/storage\/app\/media\/MemberImages\/1.jpg","party":"ANC","province":"Eastern Cape","national":0},{"id":2,"full_name":"Alexandra Lilian Amelia Abrahams","profile_pic_url":"\/storage\/app\/media\/MemberImages\/2.jpg","party":"DA","province":"Western Cape","national":0},{"id":3,"full_name":"Rachel Cecilia Adams","profile_pic_url":" ...member-count='450'></group-details>
</div>
(...) Thanks to this structure, we could relatively easily instruct a computer to look for all parliamentarians from the Northern Cape and list their names and parties.
Structured vs unstructured data
When presented with information, human beings are good at quickly categorizing it and extracting the data that they are interested in. For example, when we look at a magazine rack, provided the titles are written in a script that we are able to read, we can rapidly figure out the titles of the magazines, the stories they contain, the language they are written in, etc. and we can probably also easily organize them by topic, recognize those that are aimed at children, or even whether they lean toward a particular end of the political spectrum. Computers have a much harder time making sense of such unstructured data unless we specifically tell them what elements data is made of, for example by adding labels such as this is the title of this magazine or this is a magazine about food. Data in which individual elements are separated and labelled is said to be structured.
Let’s look now at the current list of members for the Brazilian Senate.
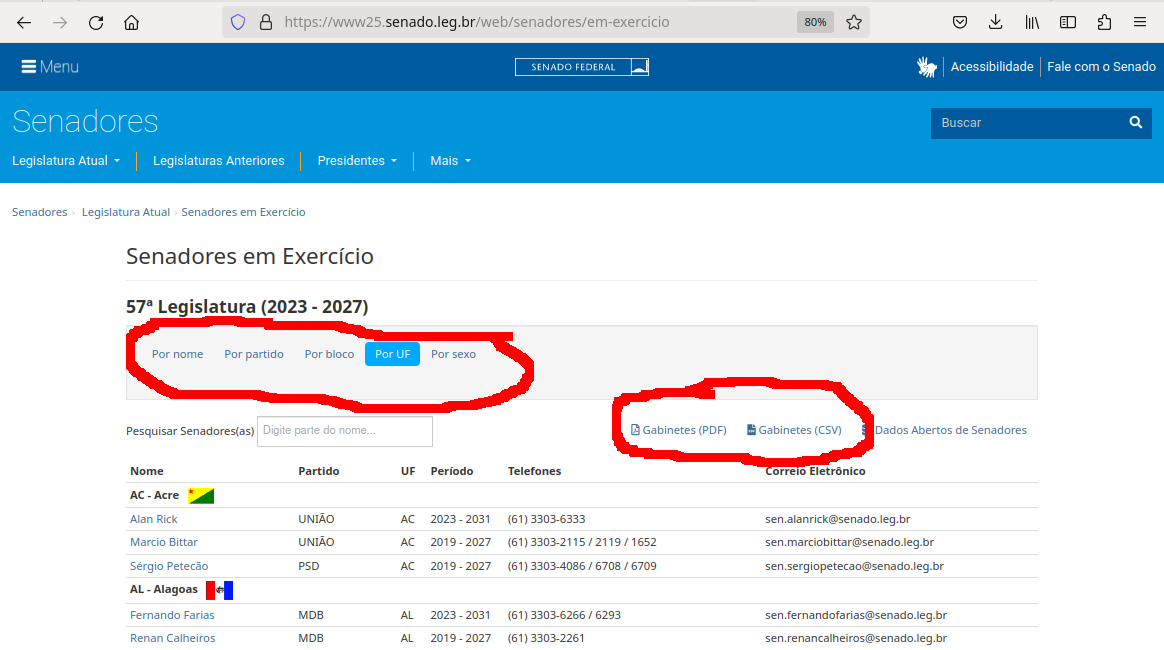 {alt=
{alt=Image of the top of the Brazilian Senate members website https://www.parliament.gov.za/group-details with options to download data as a CSV file and options for sorting based on gender, party, caucus and region circled}
This page also displays a list of names, political and geographical affiliation. Here is part of the code for this page:
OUTPUT
<div class="sf-large-table-container">
<table id="senadoresemexercicio-tabela-senadores"
class="table table-condensed"
title="Lista de senadores em exercício">
<thead>
<tr>
<th>Nome</th>
<th>Partido</th>
<th>UF</th>
<th>Período</th>
<th>Telefones</th>
<th>Correio Eletrônico</th>
</tr>
</thead>
<tbody>
<tr class="search-group-row">
<td colspan="6">
<a href="#"
name="AC"></a>
<strong>AC - Acre</strong>
<img
src="https://www.senado.leg.br/senadores/img/bandeiras/AC_p.gif"
alt="Bandeira de AC - Acre"/> </td> </tr> <tr> <td class="nowrap"><a href="https://www25.senado.leg.br/web/senadores/senador/-/perfil/5672">Alan Rick</a></td> <td>UNIÃO</td> <td>AC</td> <td>2023 - 2031</td> <td class="break-word">(61) 3303-6333</td> <td>sen.alanrick@senado.leg.br</td> </tr><tr> <td class="nowrap"><a href="https://www25.senado.leg.br/web/senadores/senador/-/perfil/285">Marcio Bittar</a></td> <td>UNIÃO</td> <td>AC</td> <td>2019 - 2027</td>(...)There are several features (circled in the image above) that make the data on this page easy to work with. The search, reorder features and display modes hint that the data is actually stored in a (structured) database before being displayed on this page. The data can be readily downloaded either as a comma separated values (.csv) file for re-use in their own database, spreadsheet or computer program or as a pdf for offline reading.
What if we wanted to download the South African parliament members dataset and, for example, compare it with the Brazilian senate dataset to analyze gender representation, or the representation of political forces in the two groups? We could try copy-pasting the entire table into a spreadsheet or even manually copy-pasting the names and parties in another document, but this can quickly become impractical when faced with a large set of data. What if we wanted to collect this information for every country that has a national legislature?
Fortunately, there are tools to automate at least part of the process. This technique is called web scraping.
Callout
“Web scraping (web harvesting or web data extraction) is a computer software technique of extracting information from websites.” (Source: Wikipedia)
Web scraping typically targets one web site at a time to extract unstructured information and put it in a structured form for reuse.
In this lesson, we will continue exploring the examples above and try different techniques to extract the information they contain. But before we launch into web scraping proper, we need to look a bit closer at how information is organized within an HTML document and how to build queries to access a specific subset of that information.
|– |– |– | | Legislative body | url | Downloadable | |– |– |– | | Canadian House of Commons | https://www.noscommunes.ca/members/fr/election-candidates | Yes | | Kenyan National Assembly | http://www.parliament.go.ke/index.php/the-national-assembly/mps | No | | US Congress | https://www.congress.gov/members | No | | Russian Duma | http://duma.gov.ru/duma/deputies/ | | | | http://api.duma.gov.ru/pages/dokumentatsiya/spisok-otrasley-zakonodatelstva | Yes | | India Rajya Sabha | https://sansad.in/rs/members | Yes | | UK House of Commons | https://members.parliament.uk/members/commons | No |
Content from Web scraping using R and rvest
Last updated on 2023-07-11 | Edit this page
Overview
Questions
- How can scraping a web site be automated?
- How can I setup a scraping project using R and rvest?
- How do I tell rvest what elements to scrape from a webpage?
- What to do with the data extracted with rvest?
Objectives
- Setting up an rvest project.
- Understanding the various elements of an rvest project.
- Scrape a website and extract specific elements.
- Plot scraped data.
- Store the extracted data.
Introduction
The rvest package allows us to scrape data from a
website. We will obtain the list of Brazilian senators and plot the
number of senators each political party has.
Setup the environment
R
library(rvest)
library(httr)
library(ggplot2)
library(stringr)
The additional libraries are - httr for controling
downloads - ggplot2 plotting the data -
stringr string manipulations to process the data
Get the website
R
BR_sen_html <- read_html(
GET("https://www25.senado.leg.br/web/senadores/em-exercicio",
timeout(600)))
# Check type of document
class(BR_sen_html)
# Examine the first few lines of the document
BR_sen_html
Now, check the type of document and examine the first few lines:
R
class(BR_sen_html)
BR_sen_html
Extract the data
Examining the source html page, all names are in a table with the id
id="senadoresemexercicio-tabela-senadores" Let us extract
this table:
R
BR_sen_df <- BR_sen_html %>%
html_element("#senadoresemexercicio-tabela-senadores") %>%
html_table()
Let us view the first few rows
``r head(BR_sen_df)
## Clean the data
Each region has three senators, but the table also
contains lines with redundant information for the region
Since we want to analyze the data, we want to remove
these lines. We also want to substitute state
name abbreviations by the full names. We first create
a dataframe with the names and abbreviations, and
then create a vector we can use to substitute abbreviations
for full names:
```r
BR_sen_regions_df <- as.data.frame(str_split_fixed(BR_sen_df$UF, " - ", 2))
BR_sen_regions_df <- BR_sen_regions_df[c(seq(1,108,4)),]
bbr_replacements <- as.character(BR_sen_regions_df$V2)
names(abbr_replacements) <- BR_sen_regions_df$V1We now remove the extra rows from the data frame:
R
BR_sen_df <- BR_sen_df[!grepl(' - ',BR_sen_df$Nome),]
and then replace the abbreviations
R
BR_sen_df$UF <- str_replace_all(BR_sen_df$UF,abbr_replacements)
Plot a portion of the data
With the clean data, we can plot the number of senators each party has,
R
g <- ggplot(BR_sen_df,aes(y=Partido))
g + geom_bar()
Save the data
Finally, we can save the data in a csv file:
R
write.csv(BR_sen_df,file="BrazilianSenateMembers.csv")
References
Content from Conclusion
Last updated on 2023-07-11 | Edit this page
Overview
Questions
- When is web scraping OK and when is it not?
- Is web scraping legal? Can I get into trouble?
- How can I make sure I’m doing the right thing?
- What can I do with the data that I’ve scraped?
Objectives
- Wrap things up
- Discuss the legal implications of web scraping
- Establish a code of conduct
Now that we have seen one way to scrape data from websites and are ready to start working on potentially larger projects, we may ask ourselves whether there are any legal implications of writing a piece of computer code that downloads information from the Internet.
In this section, we will be discussing some of the issues to be aware of when scraping websites, and we will establish a code of conduct (below) to guide our web scraping projects.
This section does not constitute legal advice
Please note that the information provided on this page is for information purposes only and does not constitute professional legal advice on the practice of web scraping.
If you are concerned about the legal implications of using web scraping on a project you are working on, it is probably a good idea to seek advice from a professional, preferably someone who has knowledge of the intellectual property (copyright) legislation in effect in your country.
Don’t break the web: Denial of Service attacks
The first and most important thing to be careful about when writing a web scraper is that it typically involves querying a website repeatedly and accessing a potentially large number of pages. For each of these pages, a request will be sent to the web server that is hosting the site, and the server will have to process the request and send a response back to the computer that is running our code. Each of these requests will consume resources on the server, during which it will not be doing something else, like for example responding to someone else trying to access the same site.
If we send too many such requests over a short span of time, we can prevent other “normal” users from accessing the site during that time, or even cause the server to run out of resources and crash.
In fact, this is such an efficient way to disrupt a web site that hackers are often doing it on purpose. This is called a Denial of Service (DoS) attack.
Since DoS attacks are unfortunately a common occurence on the Internet, modern web servers include measures to ward off such illegitimate use of their resources. They are watchful for large amounts of requests appearing to come from a single computer or IP address, and their first line of defense often involves refusing any further requests coming from this IP address.
A web scraper, even one with legitimate purposes and no intent to bring a website down, can exhibit similar behaviour and, if we are not careful, result in our computer being banned from accessing a website.
The good news is that a good web scraper, such as rvest, recognizes that this is a risk and includes measures to prevent our code from appearing to launch a DoS attack on a website. This is mostly done by inserting a random delay between individual requests, which gives the target server enough time to handle requests from other users between ours.
This is rvest’s default behaviour, and it should prevent most scraping projects from ever causing problems. To be on the safe side, however, it is good practice to limit the number of pages we are scraping while we are still writing and debugging our code. This is why in the previous section, we imposed a limit of five pages to be scraped, which we only removed when we were reasonably certain the scraper was working as it should.
Thanks to the defenses web servers use to protect themselves against DoS attacks and Scrapy’s measure to avoid inadvertently launching such an attack, the risks of causing trouble is limited.
Don’t steal: Copyright and fair use
It is important to recognize that in certain circumstances web scraping can be illegal. If the terms and conditions of the web site we are scraping specifically prohibit downloading and copying its content, then we could be in trouble for scraping it.
In practice, however, web scraping is a tolerated practice, provided reasonable care is taken not to disrupt the “regular” use of a web site, as we have seen above.
In a sense, web scraping is no different than using a web browser to visit a web page, in that it amounts to using computer software (a browser vs a scraper) to acccess data that is publicly available on the web.
In general, if data is publicly available (the content that is being scraped is not behind a password-protected authentication system), then it is OK to scrape it, provided we don’t break the web site doing so. What is potentially problematic is if the scraped data will be shared further. For example, downloading content off one website and posting it on another website (as our own), unless explicitely permitted, would constitute copyright violation and be illegal.
However, most copyright legislations recognize cases in which reusing some, possibly copyrighted, information in an aggregate or derivative format is considered “fair use”. In general, unless the intent is to pass off data as our own, copy it word for word or trying to make money out of it, reusing publicly available content scraped off the internet is OK.
Better be safe than sorry
Be aware that copyright and data privacy legislation typically differs from country to country. Be sure to check the laws that apply in your context. For example, in Australia, it can be illegal to scrape and store personal information such as names, phone numbers and email addresses, even if they are publicly available.
If you are looking to scrape data for your own personal use, then the above guidelines should probably be all that you need to worry about. However, if you plan to start harvesting a large amount of data for research or commercial purposes, you should probably seek legal advice first.
If you work in a university, chances are it has a copyright office that will help you sort out the legal aspects of your project. The university library is often the best place to start looking for help on copyright.
Web scraping code of conduct
This all being said, if you adhere to the following simple rules, you will probably be fine.
- Ask nicely. If your project requires data from a particular organisation, for example, you can try asking them directly if they could provide you what you are looking for. With some luck, they will have the primary data that they used on their website in a structured format, saving you the trouble.
- Don’t download copies of documents that are clearly not public. For example, academic journal publishers often have very strict rules about what you can and what you cannot do with their databases. Mass downloading article PDFs is probably prohibited and can put you (or at the very least your friendly university librarian) in trouble. If your project requires local copies of documents (e.g. for text mining projects), special agreements can be reached with the publisher. The library is a good place to start investigating something like that.
- Check your local legislation. For example, certain countries have laws protecting personal information such as email addresses and phone numbers. Scraping such information, even from publicly avaialable web sites, can be illegal (e.g. in Australia).
- Don’t share downloaded content illegally. Scraping for personal purposes is usually OK, even if it is copyrighted information, as it could fall under the fair use provision of the intellectual property legislation. However, sharing data for which you don’t hold the right to share is illegal.
- Share what you can. If the data you scraped is in the public domain or you got permission to share it, then put it out there for other people to reuse it (e.g. on datahub.io). If you wrote a web scraper to access it, share its code (e.g. on GitHub) so that others can benefit from it.
- Don’t break the Internet. Not all web sites are designed to withstand thousands of requests per second. If you are writing a recursive scraper (i.e. that follows hyperlinks), test it on a smaller dataset first to make sure it does what it is supposed to do. Adjust the settings of your scraper to allow for a delay between requests. By default, Scrapy uses conservative settings that should minimize this risk.
- Publish your own data in a reusable way. Don’t force others to write their own scrapers to get at your data. Use open and software-agnostic formats (e.g. JSON, XML), provide metadata (data about your data: where it came from, what it represents, how to use it, etc.) and make sure it can be indexed by search engines so that people can find it.
Going further
This lesson only provides an introduction to the practice of web scraping and highlights one of the tools available.
Happy scraping!
References
- The Web scraping Wikipedia page has a concise definition of many concepts discussed here.
- The School of Data Handbook has a short introduction to web scraping, with links to resources e.g. for data journalists.
- This blog has a discussion on some of the legal aspects of web scraping.
- morph.io is a cloud-based web scraping platform that supports multiple frameworks, interacts with GitHub and provides a built-in way to save and share extracted data.
- Software Carpentry is a non-profit organisation that runs learn-to-code workshops worldwide. All lessons are publicly available and can be followed indepentently. This lesson is heavily inspired by Software Carpentry.
- Data Carpentry is a sister organisation of Software Carpentry focused on the fundamental data management skills required to conduct research.
- Library Carpentry is another Software Carpentry spinoff focused on software skills for librarians.